I had a lot of fun recently playing with Crosswalk. I was basically testing it’s features and extensions when it hit me: I know it’s possible to write Native extensions for crosswalk Tizen, but is it possible to write Native Extensions for Crosswalk-android? How would it behave?
Crosswalk android already provides a way to load Java extensions, and the Android-NDK provides a way to call a native library from a Java method. We just have to glue those things together.
Disclaimer:
I won’t talk here about how to build a library with NDK or how to write a regular extension with Crosswalk, as those topics are already extensively covered over the Internet. I assume you already have an library.so and a working crosswalk-android extension from the Tutorials.
Adding the .so inside your apk
Crosswalk-samples includes an example application named “extensions-android“. This application builds the extension code first using an “ant” recipe and then builds the html application itself and put both inside an apk file.
By the end of the extension build process, the ant recipe opens the extension.jar file to include the META-INF information inside that file. It’s the perfect time to inject our native library inside the package.
We only have to change the build.xml recipe to include the library.
<copy file="libs/armeabi/libMyLibrary.so" todir="${build}/lib/armeabi-v7a/" />
Be sure to do it between <unjar> and <jar> as we’re taking advantage of the fact that the extension jar is being opened and closed to include the META-INF.
Performance measurement
To make a performance test I used an algorithm to find the nth prime number. The approach is the simplest (no pre-built arrays, no recursion) and dumbest (no short-cuts, no AKS, etc) one, and share the same implementation. The implementation is the following:
function findPrime(n)
{
var i, count = 0;
for (i = 1; count < n; i++) {
if (isPrime(i))
count++;
if (count == n)
break;
}
return i;
}
function isPrime(n)
{
var i = 0;
if (n == 1 || n == 2)
return true;
for (i = 2; i < n; i++) {
if (n % i == 0) {
break;
}
}
return (n == i);
}Converting it to JAVA or C would be ridiculous easy.
Performance Results
I first tried to find the 10th prime number and the result is the following:
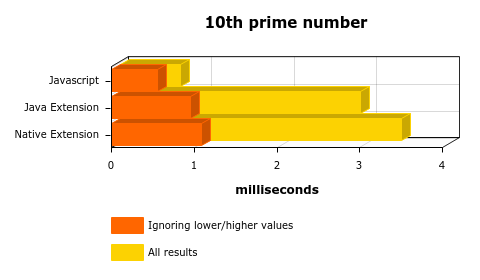
This was quite expected, right? I mean, the “context switch” between JS->JAVA or JS->JAVA->C has a price to be paid, there’s the serialization/deserialization process that takes some time to finish, and since the core operation is not really time consuming (a short iteration between 1 and 29, checking if they’re prime numbers) I can imagine why JAVA and C took more time. Let’s try again and find the 100th prime:
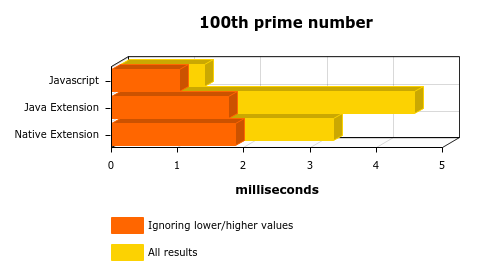
OK, It’s a bit odd, the loading time is different from execution to execution and it affects the first time the code is executed. Ignoring the higher (usually the first execution) and lower values (got lucky?) give us a more sane result, but still… What about the 10Kth prime number?
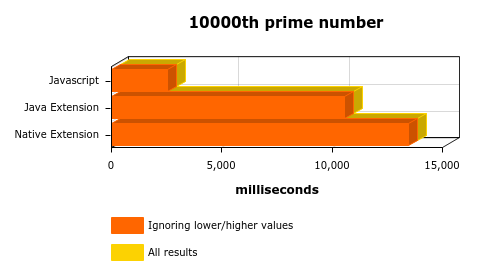
It doesn’t make any sense, JS is faster?! What’s going on?
Divisions/Modulus are expensive. Even if I build the Native Library with armeabi-v7a it gets 30% better and goes bellow 10 seconds, almost the same performance accomplished by JAVA but still worse than Javascript.
It happens that Modulus operation can be improved, and I believe that the V8 is smart enough to use some of those techniques. So, looking for primes might not be a fair way to measure performance.
Performance Results, round two
A second approach would be to avoid divisions and use only plain additions. Maybe just sum the sequence 1+2..+N, repeating it N times?
Maybe 1-2+3-4…N to avoid overflow?
function sum(n) {
var signal;
var i, j;
var total = 0;
var r1;
var start = n / 2;
for (j = 0; j <= n; j++) {
r1 = start;
signal = -1;
for (i = 0; i<= n; i++) {
r1 = r1 + (i * signal);
signal = -signal;
}
total = total + r1;
}
return total;
}
For a small sum of ten elements:
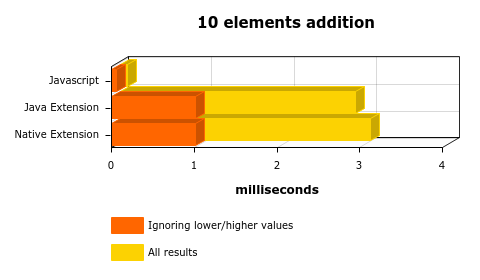
Makes sense, right? The context switch costs more than the sum of the 10 elements directly on javascript. Let’s see the 50K results:
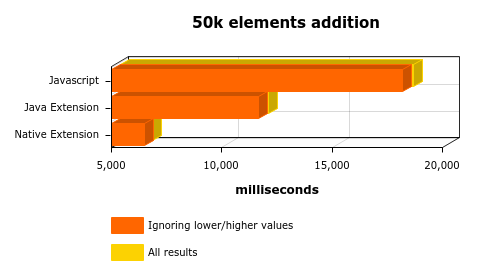
As you can see here, without space for smart optimizations on the JS side, the native results are 3x better than the javascript. Nice!
Conclusion
There’re a few lessons we learned here:
1 – The cost of going from JS->JAVA or JS->JAVA->C cannot be ignored. It was a bit less than 1ms (from the 10 additions chart). Think about that before putting a native call inside a huge loop.
2 – Consider measuring your optimizations before accepting it in your source code. Sometimes things are not obvious.
Post a Comment